CDP:Storage Index Pattern

Increasing the Efficiency of Internet Storage
Contents |
Problem to Be Solved
Due to the distribution of locations of data, Internet storage is excellent in terms of both durability and availability. However, because access is via the Internet, typically responsiveness is poor when compared to on-premises access. In some cases, high-speed search functions are not provided, requiring you to take some action on the application side when retrieving a data table for a specific user or when retrieving data for a specific range of dates.
Explanation of the Cloud Solution/Pattern
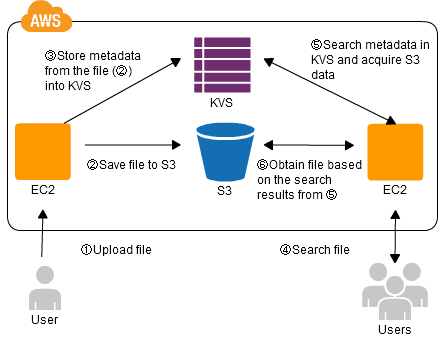
When storing data into Internet storage, metadata is stored at the same time into a KVS that has excellent searching performance, and then that data is used as an index. When searching, the KVS is used and access the Internet storage based on the result returned.
Implementation
- After storing data to Amazon Simple Storage Service (S3), store S3 metadata (keys, paths, data sizes, storage times, and the like) in SimpleDB or DynamoDB.
- When performing searches or tabulation, perform the processing using SimpleDB or DynamoDB.
- Acquire the S3 data based on the result of processing in SimpleDB or DynamoDB.
Configuration
Benefits
- This enables you to use robust high-capacity storage functions along with high-performance searching.
Cautions
- Correct search results will not be produced if there is a mismatch between the data in S3 and the KVS metadata. It is imperative that the data recording and the metadata recording be performed simultaneously.
Other
See the Web Storage Pattern.